Topics to watch at the Strata Data Conference in New York 2019
Machine learning, artificial intelligence, data engineering, and architecture are driving the data space.

The Strata Data Conferences helped chronicle the birth of big data, as well as the emergence of data science, streaming, and machine learning (ML) as disruptive phenomena. Strata attracts the leading names in the fields of data management, data engineering, analytics, ML, and artificial intelligence (AI). For nearly a decade, it’s provided a venue for developers, data and ML engineers, data architects, data scientists, and others to acquire or hone skills, explore provocative ideas, and network with peers.
Our call for speakers for Strata NY 2019 solicited contributions on the themes of data science and ML; data engineering and architecture; streaming and the Internet of Things (IoT); business analytics and data visualization; and automation, security, and data privacy. But we wanted to see what an analysis of the event’s proposal data itself might reveal about the state of the field at this point in time. So, we used a form of the Term Frequency-Inverse Document Frequency (TF/IDF) technique to identify and rank the top terms in this year’s Strata NY proposal topics—as well as those for 2018, 2017, and 2016. Which themes and topics tended to intersect or overlap with one another? Did speakers emphasize specific aspects or attributes of a theme or topic? In short, what are the issues, trends, and technologies we should be watching? [1]

Learn faster. Dig deeper. See farther.
Our analysis of the Strata NY speaker proposals surfaced several notable findings:
- ML- and AI-related terms predominate. The term “ML” is No. 2 in frequency in proposal topics; a related term, “models,” is No. 1. The term “AI,” meanwhile, is No. 3.
- Terms that relate to data engineering, data management, and data analytics dominate the top tiers of proposal topics. But although the terms and many of the practices sound familiar, the tools, use cases, and even some of the techniques have changed.
- Data engineering is an intense focus of interest and innovation, with data-in-motion—e.g., stream, time-series—starting to displace the batch-centric, data-at-rest paradigm.
- Spark has emerged as the general-purpose data processing engine of choice; interest in Hadoop is waning, although reports of its death are greatly exaggerated.
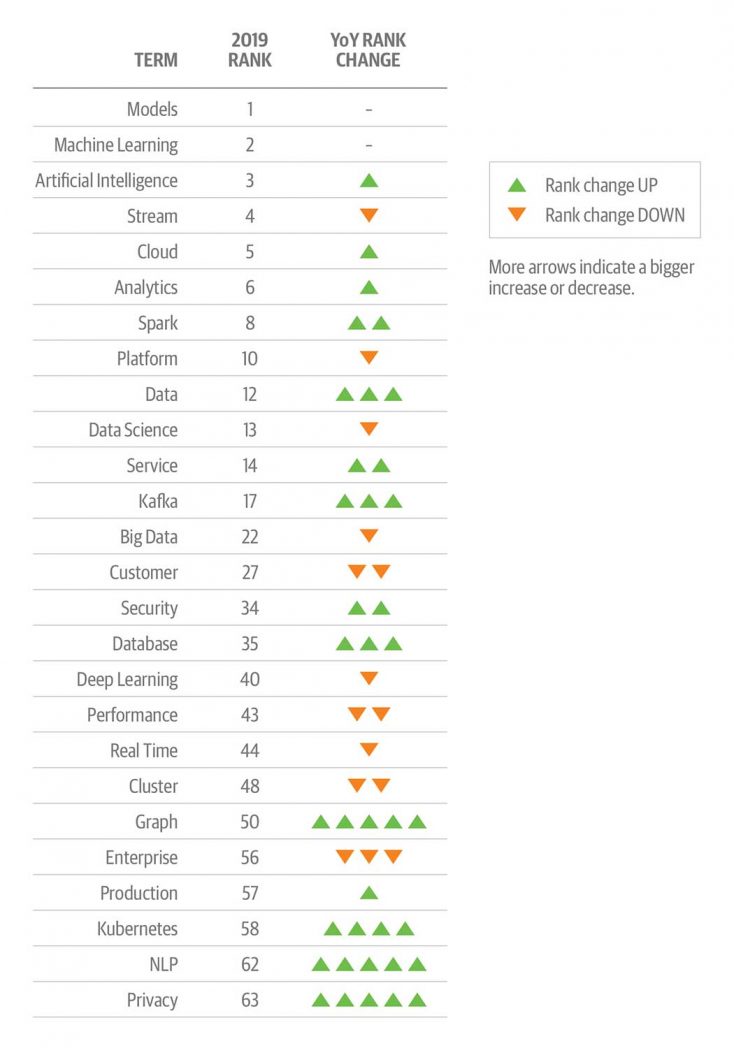
We focused this list on important industry terms and terms showing notable year-over-year changes.
ML and AI topics claim top spots
Strata has changed significantly since its inception. Nowhere is this more obvious than in the increased salience of topics that relate to ML and AI in recent Strata speaker proposal topics. ML and data science, along with, to a lesser extent, AI, were topics of note in Strata’s earliest years, too; in just the last three years, however, they’ve jumped to the top of the results. For example: even though the term “ML” (at No. 2) is unchanged from Strata NY 2018, it’s up three places from Strata NY 2017—and eight places relative to 2016.
An ML-related topic, “models,” was No. 1 again in proposals this year. It’s up two places from 2017 and up six places from 2016. (A related term, “algorithm,” seems in the midst of a long-term decline: at No. 84 this year, it’s down 20 places from 2018, and down 23 from 2017.) While ML has been a mainstay in Strata proposals for years, “AI” has not. In just the last two to three years, however, “AI” suddenly became more prevalent in proposals: in 2016, it sat at No. 253; in 2017, it climbed 226 places to No. 23; and just last year, it cracked the top five for the first time, rising to No. 4.
This year, AI sits at No. 3. This is noteworthy for several reasons: first, the top three terms in our data set relate in one way or another to ML. Second, a trend we’ve observed in other contexts is that “AI” tends to morph into a kind of metonym that gets used to describe the intersection of data, analytics, and ML.
The triumph of ML (and the surging of AI) isn’t without its ironies. For example, even though ML and ML-related concepts—a related term, “ML models,” (No. 106, +12) also improved, year over year—are rampant, ML-related tools and techniques are not. “Deep learning,” for example, fell year over year to No. 40; it peaked at Strata NY 2018 at No. 36. “Neural network” also fell slightly from 2018 (No. 221) to 2019 (No. 224)—although, it’s still up relative to 2017. “TensorFlow,” one of the most popular ML frameworks, declined in proposals this year, too—falling 35 places to No. 119.
The mixed signals about ML-related themes in this year’s proposals may indicate either a shift in focus of enterprise ML practices from tools and techniques to production-oriented solutions, or that we are approaching something like peak ML. Even if the latter is true, we expect AI’s star to continue to rise, with clear knowledge that the long history of AI research offers a case study in the consequences of hype.
Data engineering comes into its own
The term “data engineering” has exploded in popularity in recent Strata proposals topics: at No. 342 this year, it’s up 513 positions over 2018—and almost 1,900 positions over 2016.
A cluster of related terms is firmly ensconced in the top tier of proposals topics, too. “Pipeline,” for example, sits at No. 40. True, that’s down 14 positions from 2018, but it’s still up by 24 positions over 2016. Another related term, “data pipeline” (at No. 298), is down 125 positions year over year, but it’s up 132 positions relative to Strata NY 2016.
Data engineering is not a new thing, however. Since 1977, for example, the Institute of Electrical and Electronics Engineers (IEEE) has published the Data Engineering Bulletin, a quarterly journal that focuses on engineering data for use with database systems[2]. But the database—or, more precisely, the data model—is no longer the sole or, arguably, the primary focus of data engineering.
If anything, this focus has shifted to the ML or predictive model. Ironically, this shift is attested by declines in several terms that correspond to (or are synonyms for) data engineering. For example, the term “ETL”—the acronym for extract, transform, and load—dropped again in 2019, plummeting 298 places to No. 841; “ETL” is down a total of 560 places from 2016. Meanwhile, “data preparation” is in freefall: it sits at No. 1,645 this year, a collapse of 1,458 places since 2018 and 1,648 places since 2016.
What’s going on? The short answer is that the practice, scope, and, most important, site of data engineering has shifted. Increasingly, the term “data engineering” is synonymous with the practice of creating data pipelines, usually by hand. On one hand, a data pipeline resembles a legacy ETL data flow, with the exception that, instead of piping the output to a database or data warehouse, a pipeline produces data for an ML model, or (as likely) for an application or service.
In quite another respect, however, modern data engineering has evolved to support a range of scenarios that simply were not imaginable 40 years ago. ETL developers and modelers used to engineer data primarily to conform to the schema of a database model—in most cases, a relational database model. In an era of graph databases, NoSQL and document databases, text/semantic databases, time series databases, etc., the data model is no longer the focus of data engineering. Now, data engineers, data scientists, and developers need to transform data to suit specific use cases, be they data exchange via RESTful services, preparing data for use to train ML models, feeding data to ML-powered AI solutions, etc. The model has become a means to an end—i.e., doing something with data—rather than the end itself. The evolution of data engineering reflects this.
Streaming, IoT, and time series mature
The ongoing evolution of data engineering is borne out by the prominence of streaming and Internet of Things (IoT)-related terms in this year’s proposals topics. “Stream” itself was No. 4, overall, although it dropped one place, year over year, from 2018. In 2017, by way of contrast, “stream” was the No. 1 overall term.
In other words, streaming-related terms have been represented in the top tier of Strata proposal topics for half a decade now. This year, Apache Kafka, a stream-processing platform, cracked the top 20, climbing 27 places to No. 17. Apache Flink, a stream-processing framework, climbed 550 positions (year over year) to sit at No. 232; in 2016, “Flink” was No. 611. Elsewhere, “real time,” a term that correlates with the streaming use case, dropped four places, year over year, to No. 44. (“Real time” was in the Top 25 of all terms in the Strata NY 2016 proposals). “IoT,” conversely, dropped 53 positions to No. 223. It’s down a daunting 195 places from its peak in 2017, when it was the No. 28 term.
Why are some streaming-related terms trending up and others down? There’s a simple enough explanation: the problem space is changing. The early emphasis focused on the concepts themselves—i.e., streaming data, real-time data, and IoT. The mature emphasis focuses on the tools and practices developers, data architects, data engineers, and others must use to implement and support them.
To see an example of this phenomenon in real time, consider a related trending topic: time series databases. “Time series” climbed 123 positions (year over year) to No. 122; it’s up 484 positions relative to 2017. (An adjacent term, “series,” was No. 100, up 127 positions from 2018 and 307 positions from 2017.) Developers and data architects/engineers are still learning about time series databases.
One fit-for-purpose compute engine for every purpose
The battle of the general-purpose data processing engines is over: Spark is the winner. It’s the go-to choice for a range of SQL data-processing workloads and is used as a stream-processing engine, too.
In 2019, the term “Spark” improved by eight positions, year over year, to No. 8. Hadoop, by contrast, continues to decline in frequency and significance in Strata proposals. At No. 99 in 2019, “Hadoop” is close to falling out of the top 100; more important, the term has been trending downward in Strata proposals for several years: from No. 2 in 2016 to No. 10 in 2017 to No. 30 in 2018. Spark has been trending downward, too: 2018 was actually its low point (to date) in proposals topics. Spark was No. 1 in terms of frequency in 2016; in 2017, it slipped slightly to No. 2. But in 2018, it dropped out of the Top 10. Is this year’s recovery a signal of some kind—or just noise?
Our analysis suggests the former. Spark is the preferred platform for certain kinds of SQL workloads in both on-premises and cloud environments. Its use as an engine for batch ETL processing is well-attested; more recently, its Spark SQL and Spark Streaming libraries have been tapped for use in data engineering pipelines, too. Spark also sees uptake as a platform for ML processing, thanks to its spark.ml and (now-deprecated) spark.mllib libraries. But Spark isn’t the sole—or, arguably, the primary—focus of ML and AI development. Increasingly, in fact, developers, data architects, data engineers, data scientists, and others expect to be able to use different specialty engines for different purposes.
Spark is one such engine; others abound, however. In the ML world, for example, TensorFlow is popular and well-established, in spite of its year-over-year decline in proposal term positions (down 35 places). There’s also PySpark, which gives data scientists and ML engineers a simple way to parallelize Python code on Spark. In the domain of stream processing, there’s Kafka, Flink, and a spate of cloud stream-processing services (AWS Kinesis, Azure Stream Analytics). Should you use Spark, PySpark, or TensorFlow for your ML use case? Spark SQL or Hadoop (Hive, Impala, Tez, etc.) for ETL? Spark SQL or a relational database for SQL query? Spark Streaming, Amazon Kinesis, or Kafka for microbatch? And, irrespective of what you use, where are you going to put it? Output from TensorFlow, Kafka, Spark, or any other compute resource could be vectored to a time series database—or, alternately, a graph database, a NoSQL database, a relational database, an object store, or some other means of persistence. The question is which one: the topics and themes of this year’s proposals suggest that developers, data engineers, and other technologists are scrambling to acquire new domain-specific knowledge and skills. The challenge is to identify how, when, where, and why to use each of these fit-for-purpose technologies.
New trends in data architecture and data services
Another reason we expect Spark to hold steady in the top tier of proposal topics is that it remains a site of ongoing innovation and transformation, particularly with respect to where—or, more precisely, how—it runs. Developers, data and ML engineers, and data scientists are using it in non-traditional contexts to support a mix of different emerging paradigms and practices.
Spark’s resurgence coincides with several other noteworthy—and, at first glance, unrelated—developments. For example, the term “Kubernetes” posted significant growth in Strata 2019 proposals, shooting from No. 131 in 2018 to No. 58 this year. In 2017, however, Kubernetes sat at No. 518. (In 2016, conversely, it occurred just six times in all proposals.) Even as Kubernetes continues to climb, a related term, “container,” declined in 2019, falling 43 places to No. 146. “Docker,” too, continues to decline in frequency and significance: from No. 553 last year, it fell to No. 597 this year. It might seem like a stretch, but it’s possible that at least some of the interest in Kubernetes is being driven by Spark.
But let’s first discuss Kubernetes itself. It’s a tool for orchestrating and managing Docker containers. Perversely, it’s trending up even as its core enabling technologies are trending down. What gives?
The most likely explanation is that data people—architects, engineers, developers, and most other technologists—are starting to shift from tinkering and experimenting with containers to deploying and using them in production environments. As they do, their interest shifts from a focus on the basics (What is Docker? What are containers? What problems can they help me solve?) to encompass more esoteric challenges, such as the problem of managing, orchestrating, and troubleshooting jumbles of containers to support operational use cases. People can and do use Docker and its ecosystem of tools to support production use cases, too, but Kubernetes has emerged as a preferred platform for orchestrating containers, particularly with respect to microservices architecture. (The term “microservices” was at No. 409 in this year’s tally—down 107 places from 2018 and down 157 places from 2017.) Microservices give developers, data engineers, data scientists, and other people who work with data new options for running and, most important, scaling their workloads: e.g., new services (or new clusters of services) can be provisioned as needed. The upshot is that the context of compute continues to trend away from statically sized, physically instantiated systems in favor of elastic, highly virtualized resources.
Spark is implicated in this shift, as well. Traditionally, Spark deployed on physical systems or virtual machines and was controlled by a cluster resource manager, typically Mesos or YARN. But technologists are experimenting with using—or shoehorning—Spark to run in pods (the basic unit of scheduling in Kubernetes) as well as experimenting with deploying Spark clusters in Kubernetes.
Another site of architectural innovation is in serverless, or function-as-a-service (FaaS), computing. This year, “serverless” nearly cracked the top 100 of all proposal terms: it improved 1,662 positions year-over-year to sit at No. 117. It first registered in 2017 (at No. 804), but was entirely absent from 2016’s proposals topics. FaaS gives developers, data scientists, etc., a straightforward option for processing data workloads: they submit code to and have it execute in any of several cloud FaaS engines (AWS Lambda, Azure Functions, etc.) or—using Knative—in Kubernetes. The rapid rise of “serverless” in proposals topics suggests that, it, too, has become a trending topic in data and analytics. That we see rising interest in infrastructure topics in a conference focused on data and analytics points to trends we see across all of the sectors we track—trends which we reference in a coming report on Next Architecture, exploring the confluence of cloud, containers, orchestration, and microservices as increasingly the software development architecture of choice for many organizations.
Big data, analytics, security, and other items of note
The term “analytics” rose in the ranks this year (No. 6, +2), reversing a slight decline that began in 2017 and persisted through 2018. (It was No. 8 in both years.) “Analytics” occupies the same position it did in 2016, the first year for which Strata NY proposals data is available. This isn’t surprising: analytics is one of Strata’s founding pillars. Another founding pillar, “big data,” seems to be in the midst of a protracted decline: at No. 22, it’s down five positions year over year, and down 17 positions since 2016, when it was the No. 5 term. Is it possible that “big data” is somehow becoming less of a thing, per se?
Sure, in the same way that “SQL” (No. 105, -17) or even “Python” (No. 136, -35) are also becoming “less of a thing.” The most likely explanation is that the term itself is no longer as useful or valuable as it once was. To speak of “big data” a decade ago was to describe a then-new socio-technical phenomenon. Big data changed the way we thought about, managed, and used data. It made us rethink the tools and processes we used to generate, collect, move, engineer, and store data.
Ten years on, big data isn’t in any sense an anomalous phenomenon; if anything, it’s a description of the status quo. Nor is big data itself a topic of controversy, confusion, uncertainty, or, even, ignorance. The questions, concerns, problems, challenges, and use cases we identified with big data have all moved up the stack, so to speak. It’s no accident that “NoSQL,” a term that, a decade ago, was effectively twinned with big data, continues to fall into obscurity in proposal topics. “NoSQL” dropped 116 places to No. 1,713, following a brief recovery last year. It’s down a staggering 1,325 places since 2016. This doesn’t mean NoSQL is irrelevant or falling into disuse; it does suggest the term isn’t as useful, valuable, controversial, confusing, etc., as it was even three years ago.
This is true of a spate of once-dominant topics. “BI,” short for “business intelligence,” dropped 19 places, year over year, to No. 163. It’s down 137 places from 2017, but, paradoxically, up six places relative to 2016. Similarly, “data warehouse” fell 211 places to No. 645. Believe it or not, “data warehouse” had rallied at recent Strata events: it was No. 434 at Strata 2018 and No. 561 at Strata 2016. And “self-service,” one of the most important trends in data and analytics in the new millennium, fell 187 places to No. 719, trailing “data warehouse.” It’s down 280 places from 2017.
Much as some business people, data scientists, data engineers, etc., might long for the death of the data warehouse, BI tools, and related tools/technologies, they likely aren’t going anywhere. They, too, are becoming less controversial, confusing, or valuable as sites of discussion, innovation, or interest.
One topic that is a renewed area of interest is security. A mainstay of the Top 50 in Strata proposal topics, “security” improved 13 places this year to sit at No. 34. This partially reversed a steep drop in 2018, when “security” fell to No. 47. In 2017 and 2016, “security” sat at Nos. 22 and 20, respectively.
Concluding thoughts
The up-again, down-again volatility of “security” as a trending topic gets at something else, too: just because a concept seems to be declining in frequency doesn’t mean the decline is irreversible. With respect to security, for example, several factors—e.g., the introduction of new (more stringent) privacy regulations; one or more widely publicized data breaches; embarrassing ethical misprisions involving the misuse of personally identifiable information; experimentation with new architectures, such as microservices, that pose unknown security risks—could create the conditions for a resurgence. There’s something else, too: information security is a hard problem area. It imposes unwelcome constraints and entails unwelcome compromises. Security best practices are often at odds with the needs or preferences of different kinds of users. There’s constant pressure to alter, weaken, or eliminate security controls. New practices or paradigms (such as bring-your-own device, self-service, and even cloud) periodically emerge to challenge something about the security status quo. In spite of—or because of—attempts to weaken, eliminate, or replace it, information security always comes surging back as a hot or trending topic.
This is true of SQL, too. Developers disdain it, data scientists are more comfortable with other languages (such as Python), and business people have never, ever cottoned to it. But SQL is the lingua franca of data access—all relational databases (and many non-relational databases) “speak” it—as well as a powerful tool for describing, manipulating, and transforming data. This year, SQL sits at No. 105. That’s a decline of 17 positions from Strata NY 2018, and 67 positions from 2016. But SQL isn’t going anywhere. Relational databases aren’t going anywhere. If anything, SQL is in decline because, after a decade or more of furious innovation, it is no longer a red-hot focus of activity.
Security and SQL have staying power. Many trends and topics don’t, however. Some are like supernovae: they burst into prominence and then flame out into obscurity. Take “DataOps,” for example. As of Strata NY 2019, it sits at No. 518 in our analysis of proposals topics. That’s an increase of 1,532 positions over 2018 and a huge 3,056-place increase over 2017, when “DataOps” occurred just 10 times in all proposals. (“DataOps” wasn’t used in a single proposal in 2016.) But it’s still a relatively lackluster result, especially in light of how much emphasis BI, analytics, data management, and other vendors are giving to it. By way of contrast, the term “DevOps” occurs with much greater frequency in this year’s Strata proposals: it’s at No. 323 in our analysis, far outpacing DataOps, and up 236 places from 2018. “DevOps” has climbed 2,537 places since 2016.
Will “DataOps” crack the top 250 next year? Will it surge into the top 100—or, even the top 25—of topics? This much seems obvious: if it truly is disruptive, useful, confusing, and/or controversial, “DataOps” will ascend the ranks of Strata proposal topics. There’s plenty of precedent, after all.