Recommendations for all of us
Don’t misinterpret behavioral data if you want to be fair to everyone in the household
 Young people at the beach. (source: The Royal Library, Denmark, on Wikimedia Commons)
Young people at the beach. (source: The Royal Library, Denmark, on Wikimedia Commons)
If you live in a household with a communal device like an Amazon Echo or Google Home Hub, you probably use it to play music. If you live with other people, you may find that over time, the Spotify or Pandora algorithm seems not to know you as well. You’ll find songs creeping into your playlists that you would never have chosen for yourself. The cause is often obvious: I’d see a whole playlist devoted to Disney musicals or Minecraft fan songs. I don’t listen to this music, but my children do, using the shared device in the kitchen. And that shared device only knows about a single user, and that user happens to be me.
More recently, many people who had end-of-year wrap up playlists created by Spotify found that they didn’t quite fit, including myself:

Learn faster. Dig deeper. See farther.
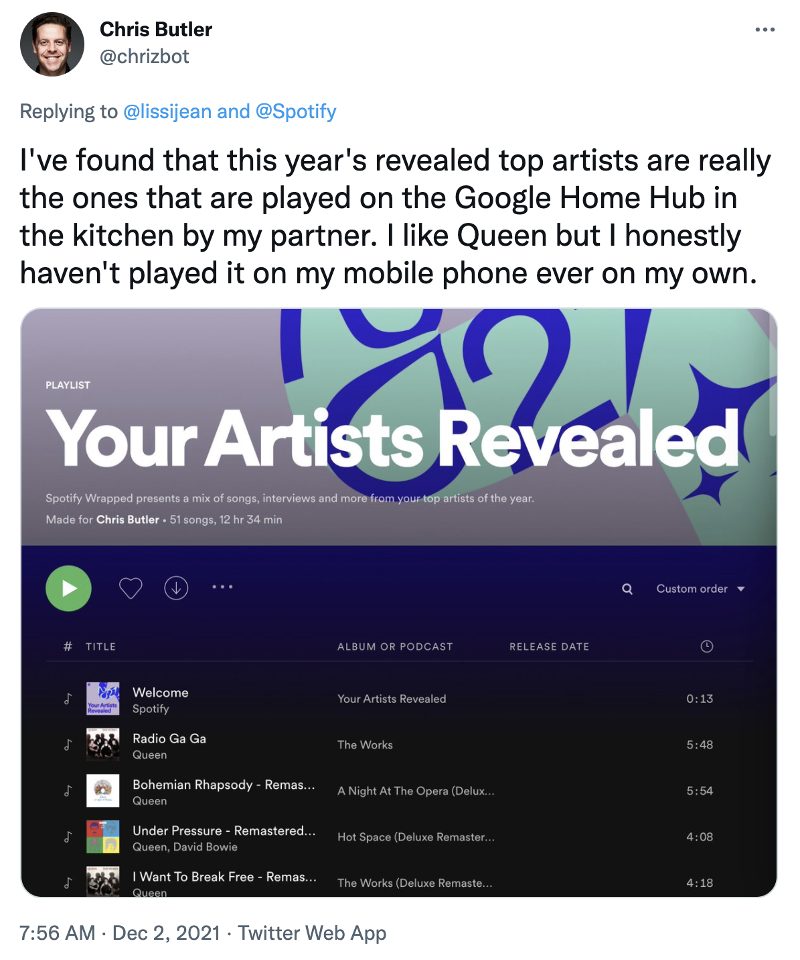
Source: https://twitter.com/chrizbot/status/1466436036771389463
This kind of a mismatch and narrowing to one person is an identity issue that I’ve identified in previous articles about communal computing. Most home computing devices don’t understand all of the identities (and pseudo-identities) of the people who are using the devices. The services then extend the behavior collected through these shared experiences to recommend music for personal use. In short, these devices are communal devices: they’re designed to be used by groups of people, and aren’t dedicated to an individual. But they are still based on a single-user model, in which the device is associated with (and collects data about) a single identity.
These services should be able to do a better job of recommending content for groups of people. Platforms like Netflix and Spotify have tried to deal with this problem, but it is difficult. I’d like to take you through some of the basics for group recommendation services, what is being tried today, and where we should go in the future.
Common group recommendation methods
After seeing these problems with communal identities, I became curious about how other people have solved group recommendation services so far. Recommendation services for individuals succeed if they lead to further engagement. Engagement may take different forms, based on the service type:
- Video recommendations – watching an entire show or movie, subscribing to the channel, watching the next episode
- Commerce recommendations – buying the item, rating it
- Music recommendations – listening to a song fully, adding to a playlist, liking
Collaborative filtering (deep dive in Programming Collective Intelligence) is the most common approach for doing individual recommendations. It looks at who I overlap with in taste and then recommends items that I might not have tried from other people’s lists. This won’t work for group recommendations because in a group, you can’t tell which behavior (e.g., listening or liking a song) should be attributed to which person. Collaborative filtering only works when the behaviors can all be attributed to a single person.
Group recommendation services build on top of these individualized concepts. The most common approach is to look at each individual’s preferences and combine them in some way for the group. Two key papers discussing how to combine individual preferences describe PolyLens, a movie recommendation service for groups, and CATS, an approach to collaborative filtering for group recommendations. A paper on ResearchGate summarized research on group recommendations back in 2007.
According to the PolyLens paper, group recommendation services should “create a ‘pseudo-user’ that represents the group’s tastes, and to produce recommendations for the pseudo-user.” There could be issues about imbalances of data if some members of the group provide more behavior or preference information than others. You don’t want the group’s preferences to be dominated by a very active minority.
An alternative to this, again from the PolyLens paper, is to “generate recommendation lists for each group member and merge the lists.” It’s easier for these services to explain why any item is on the list, because it’s possible to show how many members of the group liked a particular item that was recommended. Creating a single pseudo-user for the group might obscure the preferences of individual members.
The criteria for the success of a group recommendation service are similar to the criteria for the success of individual recommendation services: are songs and movies played in their entirety? Are they added to playlists? However, group recommendations must also take into account group dynamics. Is the algorithm fair to all members of the group, or do a few members dominate its recommendations? Do its recommendations cause “misery” to some group members (i.e., are there some recommendations that most members always listen to and like, but that some always skip and strongly dislike)?
There are some important questions left for implementers:
- How do people join a group?
- Should each individual’s history be private?
- How do issues like privacy impact explainability?
- Is the current use to discover something new or to revisit something that people have liked previously (e.g. find out about a new movie that no one has watched or rewatch a movie the whole family has seen together since it is easy)?
So far, there is a lot left to understand about group recommendation services. Let’s talk about a few key cases for Netflix, Spotify, and Amazon first.
Netflix avoiding the issue with profiles, or is it?
Back when Netflix was primarily a DVD service (2004), they launched profiles to allow different people in the same household to have different queues of DVDs in the same account. Netflix eventually extended this practice to online streaming. In 2014, they launched profiles on their streaming service, which asked the question “who’s watching?” on the launch screen. While multiple queues for DVDs and streaming profiles try to address similar problems they don’t end up solving group recommendations. In particular, streaming profiles per person leads to two key problems:
- When a group wants to watch a movie together, one of the group’s profiles needs to be selected. If there are children present, a kids’ profile will probably be selected. However, that profile doesn’t take into account the preferences of adults who are present.
- When someone is visiting the house, say a guest or a babysitter, they will most likely end up choosing a random profile. This means that the visitor’s behavioral data will be added to some household member’s profile, which could skew their recommendations.
How could Netflix provide better selection and recommendation streams when there are multiple people watching together? Netflix talked about this question in a blog post from 2012, but it isn’t clear to customers what they are doing:
That is why when you see your Top10, you are likely to discover items for dad, mom, the kids, or the whole family. Even for a single person household we want to appeal to your range of interests and moods. To achieve this, in many parts of our system we are not only optimizing for accuracy, but also for diversity.
Netflix was early to consider the various people using their services in a household, but they have to go further before meeting the requirements of communal use. If diversity is rewarded, how do they know it is working for everyone “in the room” even though they don’t collect that data? As you expand who might be watching, how would they know when a show or movie is inappropriate for the audience?
Amazon merges everyone into the main account
When people live together in a household, it is common for one person to arrange most of the repairs or purchases. When using Amazon, that person will effectively get recommendations for the entire household. Amazon focuses on increasing the number of purchases made by that person, without understanding anything about the larger group. They will offer subscriptions to items that might be consumed by a whole household, but mistaking those for the purchases of an individual.
The result is that the person who wanted the item will never see additional recommendations they may have liked if they aren’t the main account holder–and the main account holder might ignore those recommendations because they don’t care. I wonder if Amazon changes recommendations to individual accounts that are part of the same Prime membership; this might address some of this mismatch.
The way that Amazon ties these accounts together is still subject to key questions that will help create the right recommendations for a household. How might Amazon understand that purchases such as food and other perishables are for the household, rather than an individual? What about purchases that are gifts for others in the household?
Spotify is leading the charge with group playlists
Spotify has created group subscription packages called Duo (for couples) and Premium Family (for more than two people). These packages not only simplify the billing relationship with Spotify; they also provide playlists that consider everyone in the subscription.
The shared playlist is the union of the accounts on the same subscription. This creates a playlist of up to 50 songs that all accounts can see and play. There are some controls that allow account owners to flag songs that might not be appropriate for everyone on the subscription. Spotify provides a lot of information about how they construct the Blend playlist in a recent blog post. In particular, they weighed whether they should try to reduce misery or maximize joy:
“Minimize the misery” is valuing democratic and coherent attributes over relevance. “Maximize the joy” values relevance over democratic and coherent attributes. Our solution is more about maximizing the joy, where we try to select the songs that are most personally relevant to a user. This decision was made based on feedback from employees and our data curation team.
Reducing misery would most likely provide better background music (music that is not unpleasant to everyone in the group), but is less likely to help people discover new music from each other.
Spotify was also concerned about explainability: they thought people would want to know why a song was included in a blended playlist. They solved this problem, at least partly, by showing the picture of the person from whose playlists the song came.
These multi-person subscriptions and group playlists solve some problems, but they still struggle to answer certain questions we should ask about group recommendation services. What happens if two people have very little overlapping interest? How do we detect when someone hates certain music but is just OK with others? How do they discover new music together?
Reconsidering the communal experience based on norms
Most of the research into group recommendation services has been tweaking how people implicitly and explicitly rate items to be combined into a shared feed. These methods haven’t considered how people might self-select into a household or join a community that wants to have group recommendations.
For example, deciding what to watch on a TV may take a few steps:
- Who is in the room? Only adults or kids too? If there are kids present, there should be restrictions based on age.
- What time of day is it? Are we taking a midday break or relaxing after a hard day? We may opt for educational shows for kids during the day and comedy for adults at night.
- Did we just watch something from which an algorithm can infer what we want to watch next? This will lead to the next episode in a series.
- Who hasn’t gotten a turn to watch something yet? Is there anyone in the household whose highest-rated songs haven’t been played? This will lead to turn taking.
- And more…
As you can see, there are contexts, norms, and history are all tied up in the way people decide what to watch next as a group. PolyLens discussed this in their paper, but didn’t act on it:
The social value functions for group recommendations can vary substantially. Group happiness may be the average happiness of the members, the happiness of the most happy member, or the happiness of the least happy member (i.e., we’re all miserable if one of us is unhappy). Other factors can be included. A social value function could weigh the opinion of expert members more highly, or could strive for long-term fairness by giving greater weight to people who “lost out” in previous recommendations.
Getting this highly contextual information is very hard. It may not be possible to collect much more than “who is watching” as Netflix does today. If that is the case, we may want to reverse all of the context to the location and time. The TV room at night will have a different behavioral history than the kitchen on a Sunday morning.
One way to consider the success of a group recommendation service is how much browsing is required before a decision is made? If we can get someone watching or listening to something with less negotiation, that could mean the group recommendation service is doing its job.
With the proliferation of personal devices, people can be present to “watch” with everyone else but not be actively viewing. They could be playing a game, messaging with someone else, or simply watching something else on their device. This flexibility raises the question of what “watching together” means, but also lowers the concern that we need to get group recommendations right all the time. It’s easy enough for someone to do something else. However, the reverse isn’t true. The biggest mistake we can make is to take highly contextual behavior gathered from a shared environment and apply it to my personal recommendations.
Contextual integrity and privacy of my behavior
When we start mixing information from multiple people in a group, it’s possible that some will feel that their privacy has been violated. Using some of the framework of Contextual Integrity, we need to look at the norms that people expect. Some people might be embarrassed if the music they enjoy privately was suddenly shown to everyone in a group or household. Is it OK to share explicit music with the household even if everyone is OK with explicit music in general?
People already build very complex mental models about how services like Spotify work and sometimes personify them as “folk theories.” The expectations will most likely change if group recommendation services are brought front and center. Services like Spotify will appear to be more like a social network if they don’t bury who is currently logged into a small profile picture in the corner; they should show everyone who is being considered for the group recommendations at that moment.
Privacy laws and regulations are becoming more patchwork not only worldwide (China has recently created regulation of content recommendation services) but even within states of the US. Collecting any data without appropriate disclosure and permission may be problematic. The fuel of recommendation services, including group recommendation services, is behavioral data about people that will fall under these laws and regulations. You should be considering what is best for the household over what is best for your organization.
The dream of the whole family
Today there are various efforts for improving recommendations to people living in households. These efforts miss the mark by not considering all of the people who could be watching, listening, or consuming the goods. This means that people do not get what they really want, and that companies get less engagement or sales than they would like.
The key to fixing these issues is to do a better job of understanding who is in the room, rather than making assumptions that reduce all the group members down to a single account. To do so will require user experience changes that bring the household community front and center.
If you are considering how you build these services, start with the expectations of the people in the environment, rather than forcing the single user model on people. When you do, you will provide something great for everyone who is in the room: a way to enjoy something together.